

Imagine you’re a data engineer at a Fortune 1000 company. Your company has thousands of databases and 14,000 business intelligence users. You use data virtualization to create data views, configure security, and share data. Easy, right?
Sometimes, but it’s getting harder. Six new frontiers lie ahead.
One: Streaming Data Virtualization
Most every new device, vehicle, or piece of robotic equipment has embedded sensors. Supply chain managers want to anticipate changes in the weather. All this data is in motion. But first-generation data virtualization tools are designed for data at rest. For example, here’s a request data engineers are starting to get a lot:
“Show me the maintenance history for machine 123 and up-to-the-second sensor readings.”
Streaming data preparation turns data in motion into streaming tables. The rows in the table update with each event. Instead of connecting to data on disk, they connect directly to streams. Kafka, MQTT, drone data, weather feeds, IoT sensor readings. They provide tools to clean, aggregate and augment events.
Streaming data virtualization turns live tables into a data virtualization data source.
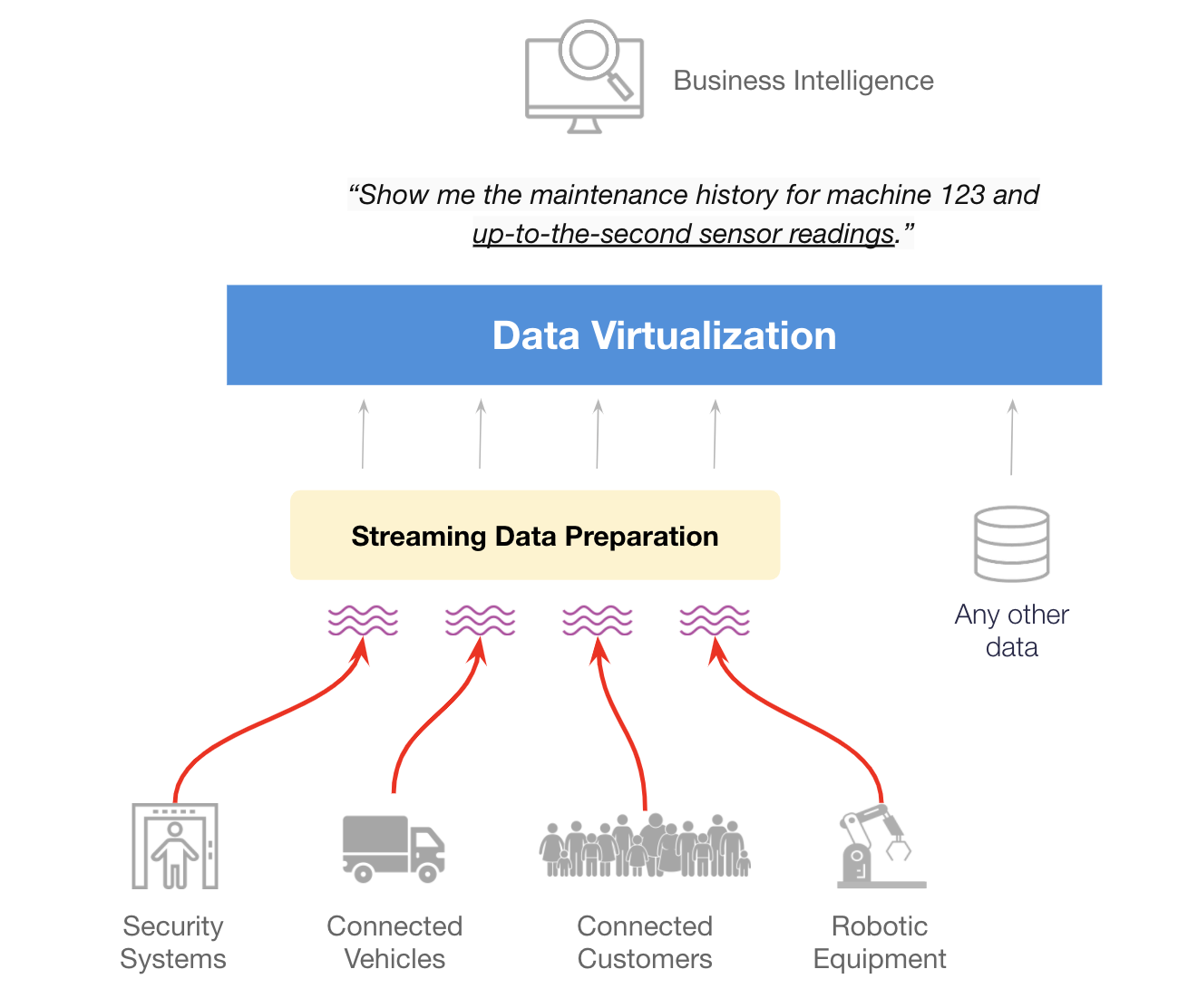
For digital transformation, managing data in motion is a new, critical imperative. Streaming data virtualization turns data in motion into virtualized insight. It’s the first new frontier for data virtualization.
Two: Virtualized Data Science Model Output
AI and data science are white-hot technology fields. Data scientists devour data, and they create algorithms. And those algorithms produce derived data that represent predictions based on raw data. A new frontier for data virtualization is to deliver the inputs into and output from those models as data services, consistent for all relevant teams, stakeholders, and applications. The typical business request goes like this:
“Show me what customer X has purchased and what he is likely to buy next.”
But the villain in the data science love story is the data science sandbox. Data scientist teams often create private data stores to develop their algorithms. Data science sandboxes are like a laboratory for mathematicians.
The trick is to liberate algorithms from the sandbox and put them into operational use. Some companies re-write algorithms to ensure performance, security, and scale. Two new pieces of technology help reduce this friction.
First, data virtualization accelerates data science, by creating consistent views of the data available to the teams that evaluate algorithms to develop accurate and useful models.

[Caption: 1) Data virtualization provides high-quality data for research, and 2) accelerates the discovery of effective algorithms and models, and their deployment from the lab to production via Model Ops. The output of predictions is used by operational systems (e.g., business intelligence.]
Once a data scientist team finds promising algorithms, what next?
A new option is to load them into “model operationalization,” or Model Ops, tools. Model Ops tools manage the lifecycle and deployment of algorithms. It’s like a parking garage for algorithms. A data scientist parks an algorithm that predicts what a customer may buy next in the Model Ops tool. A data engineer can choose a model from the garage and deploy it into the data virtualization fabric. Analysts can now ask what a customer is likely to buy at the same time as what they already bought.
Virtualized data science helps the enterprise become more AI-driven. Data science teams get better data. It improves team collaboration. More and better ideas are found. And used. It’s an innovative, better way to turn math into insights and ROI.
Three: Data-as-a-Service (DaaS)
APIs are the application-to-application plumbing of modern digital business. In some cases, the API IS the business model. But APIs must be managed like products, and that’s where API management tools come in.
“Can you slap an API on that data?” is another common request data engineers get today. Sure, you can throw a REST interface on your service, but should you? Who’s calling it? How many times? Will the business charge a fee to access the API? How much?
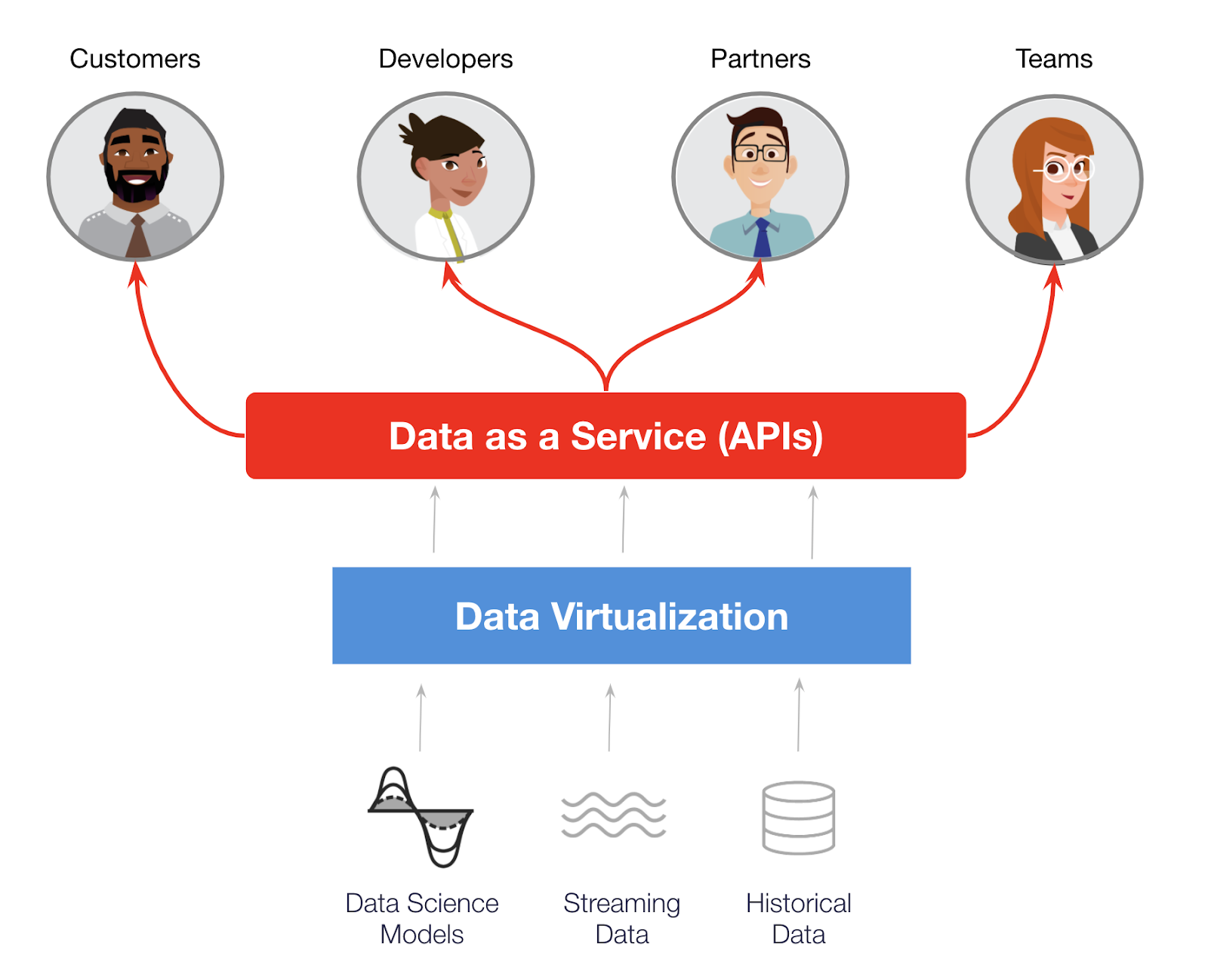
DaaS tools let you select data views you want to expose as an API. API Management tools manage those APIs as products.
Turning virtualized data into services is the third frontier of data virtualization.
Four: Virtualized Metadata Harvesting
In March of 2020, Panera Bread decided to turn their business model upside down. They turned 2,000 restaurants from cafes to grocers. Now, they sell their ingredients so customers can eat Panera-quality food at home.
This kind of business transformation requires metadata or data about data. Panera has data about their data in one place. Having instant access to menu, recipe, supplier, and inventory data helped them change their business model in ten days.
Noel Nitecki of Panera says, “data, for us, is an afterthought.”
Data virtualization can make it easy for metadata tools to harvest its metadata. So, the fourth frontier of data virtualization is to power metadata harvesting.
Five: Data Virtualization as a Team Sport
In the future, most every worker will be a knowledge worker. They all need data, and they need to share the same view of data. But not every worker understands the complexity of data. “Citizen tools” make it easy for non-engineers to manage data. These tools are the fifth frontier of data virtualization.
For example, Panera’s 50,000 employees share one view of data. So when they decided to offer their ingredients for sale, all teams were able to work as one team. This includes:
- E-commerce channel managers
- Menu management
- Point of sale
- Panera’s food innovation team
- The “clean ingredients” team
- Chefs
- Calorie counters
- Supply chain managers
- Food quality assurance
- Consumer and sensory testing
And, IT needs tools designed for them. For example:
- Data scientists want to manage data with Jupyter notebooks
- Data engineers need tools to optimize performance
- Automation engineers need real-time tools
Data virtualization must help all these personas with tools designed for them.
Six: Integrated Data Quality
Quality is job one for data engineers. Data quality tools help clean, deduplicate, and validate data. Data engineers reasonably expect data quality capabilities to be part of data virtualization. Native data quality tools for data virtualization is the sixth frontier.
With native data quality tools, consumers can trust the integrity of their data. The resulting analytical insights will be more accurate and impactful for the business.
Who will be the Tesla of Data Virtualization?
Data is the solar power (not the oil!) of today’s digital business. These six frontiers represent the future. The driverless, electric business vehicle of tomorrow, if you will. Who will be the Tesla of modern Data Virtualization?
If you would like to learn more about TIBCO Data Virtualization, head here for more info.




