

When I speak about APIs, digital transformation, and the state of web architecture around the world, it seems most of the questions I get center around microservices. Microservices are the implementation of an architectural style that focuses heavily on maintaining independence between the components represented by a set of web services to maximize code reuse, maintainability, and stability for a system, exposing their functionality typically through a set of web services that adhere closely to RESTful best practices.
I’ll be frank—when I first read Martin Fowler’s seminal description of microservices and how to implement them, I was confused. It turns out I wasn’t alone—many of the questions I’m asked about them betray a basic confusion over what they are and how they work. It wasn’t until I began implementing a microservices architecture for a side project that I truly began to understand their power. I drew the diagram below to visually explain to myself how a microservices architecture might fit into a modern standard infrastructure—one that doesn’t have the luxury to scrap its legacy in favor of building microservices from the ground up.
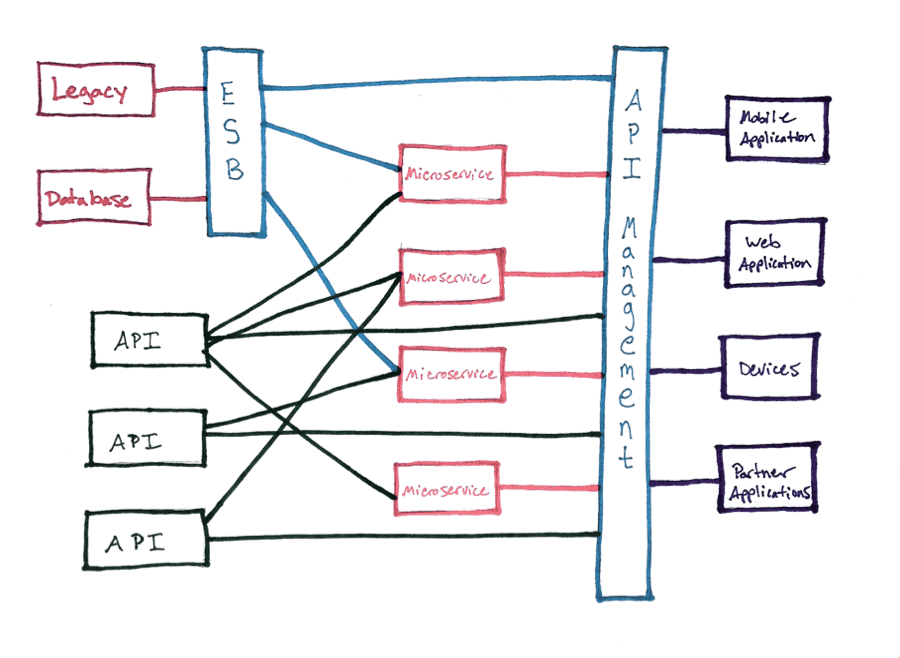 You’ll see I place microservices here at a couple of layers—both serving existing APIs as well as consuming, compositing, and serving new APIs. I think it’s that last bit that intrigues most people—they wonder why that would be necessary.
You’ll see I place microservices here at a couple of layers—both serving existing APIs as well as consuming, compositing, and serving new APIs. I think it’s that last bit that intrigues most people—they wonder why that would be necessary.
The only organizations able to fully leverage the benefits of a microservices architecture are those who are able to build—or rebuild—their IT infrastructure from the ground up. Splitting your monolithic application into smaller, independent applications is not a task most teams are able to perform in a reasonable amount of time while maintaining existing code and continuously building new features and functionality. For most teams, this will be an iterative process to slowly replace existing systems as they go, only fully leveraging microservices for new applications. The pattern I’ve described in this diagram is one way to accomplish this—to present a facade that looks like it’s built using microservices and abstract the interface away from the business logic, making it easier to refactor and replace the underlying systems down the line.
“Isn’t this just SOA?”
It’s a bit of a mind shift for some teams, but one that most deem worth the hassle. When I talk to teams about adopting microservices and their main benefits—code reusability, better environmental controls, more efficient scalability, etc.—that gets them pretty excited. But, inevitably, there’s that one person in the back of the room giving me that look. You know who I’m talking about. They’ve heard all this before. It was the promise of CORBA and DCOM and Jini and EJBs and SOAP.
“Isn’t this just Service Oriented Architecture?” they ask. “We’ve been down this path.”
The efficient reuse of data and functionality has been the architectural promise since we started networking computers to each other. Instead of having a single application that handles everything, we can have multiple applications running on different servers, both local and remote, each responsible for their own functionality, each independently maintained and updated and altered as needed, a sum of services that will be greater than any single whole application—a paradise of massively parallel computing and reusability.
We have the benefit of hindsight to know where this all went. SOA required massive overhauls of existing systems, often adopting tools that had vendor-specific quirks that made any sense of real standardization a futile pursuit. At the same time, it allowed for new and interesting business models to develop as teams took this idea of networked services and opened it to the web. So, at just about the same time people started decrying the failure of SOA, they were building on it in a more expansive, web-centered way.
Mobile drove much of this move to get that data out of the data center. But the traditional methods of SOA—the transport of data using XML in particular—proved to be a bit much for the constrained environments represented by early mobile devices. SOAP and other XML-RPC style web service APIs emerged to resolve this, which then gave way to the easier to parse and transport JSON.
The architectural standards also changed, moving away from remote procedural calls to something that adhered a bit more closely to the HTTP that was being used by these devices to transport that data. REST emerged as the dominant way that web service APIs communicate across HTTP. And, for developers coming up during this time, it is also the holy grail to allow for more efficient distributed computing, both across networks and within larger applications. For a lot of us, RESTful APIs are the hammer we use to drive every computing problem we face, whether it’s nail-shaped or not.
And if REST done right means focusing on the resources, relationships, and representations of the business objects in our system, it doesn’t really make sense to serve that from an old, monolithic system. It’s like putting Conway’s Law into reverse—if we’re presenting a layer made up of resources that are independent and stateless, shouldn’t we build our applications to serve those resources in a way that’s also stateless and independent?
And so here we are, talking about microservices as the solution. But that guy in the back of the room? He’s right—microservices is still trying to deliver on the promises of SOA.
Microservices come at a time when we have an interesting inflection point of technologies—fast broadband networking, ubiquitous wireless connections, blazing processors, cheap memory, machine virtualization, application containerization and so much more. It’s an incredibly exciting time to be a developer. It’s tempting to look at all of this as something brand new. While the implementations are new, the ideas—and the challenges—go back for decades.
Those who don’t learn from history…
There’s a reason I’m dredging up all of this history. I’m concerned we may be setting ourselves up to repeat the past if we don’t spend some time learning from it. SOA emerged with a number of challenges that doomed many an implementation. Some of it was due to the proprietary quirks introduced by different vendors and the complexity of their solutions. In reaction, the folks who have adopted and promoted REST as a solution have resisted standardization completely, opting instead to implement solutions that follow best practices but can still differ dramatically from other implementations. This reactionary approach definitely has some benefits—it gets teams building services without getting too bogged down in the rules—but it has, in many cases, already led to some confusion and frustration among teams and the developers they’re targeting with their APIs.
Many of SOA’s initial problems in terms of performance and overhead have been solved either by adopting better technologies to serve this data—HTTP, REST, JSON, etc.—or by the simple fact that our devices have become better at parsing and handling all that data. But, I’ve seen a number of teams fall into many of the same traps that SOA set. The three I see the most often are:
- Service discoverability
- Application governance and security
- Interface consistency
These problems doomed a number of SOA implementations. As the number of services increases in any given system, these issues will only increase as well. The tools to address these issues have evolved, but they still require cultural changes and discipline within an organization to use them correctly. But taking the time to adopt these tools and practices early in your project can ensure you don’t repeat the cataclysmic SOA mistakes of the past.
Service discoverability
The more services you add to your system —and the more developers you have building services—the more difficult it can be to track what’s available. A variety of technologies emerged to resolve this in SOA, including the Web Services Definition Language (WSDL), the Universal Description, Discovery, and Integration spec (UDDI), and the Web Application Description Language (WADL). As SOAP emerged as the early leader in web services under SOA, the WSDL became the de facto way to describe what services were available. This worked out remarkably well as many languages released SOAP clients that read the WSDL and automatically produced libraries to consume the services it described.
The problem with WSDL, WADL, and all the others is that they required a single registry for all services in the system. For larger systems with many services, this grew the description document to many megabytes of information. The size of these documents combined with the complexity of parsing XML, particularly in constrained environments like mobile phones, made this method unsuitable for a lot of implementations. The decentralized nature of microservices adds to the complexity of these solutions.
The RESTful API community has been blessed with a number of description formats that go a long way toward addressing the limitations of past solutions. Swagger, in particular, has emerged as a clear leader, signaled in their recent name change to the Open API Initiative (OAI). Eschewing the more complex formatting of XML for the leaner JSON and YAML formats, the OAI is a leaner way to describe the services available. However, it’s still designed to be centralized in an individual document. The better way to approach this is to write an OAI spec for each set of services delivered by a single microservice and to let those microservices maintain their own descriptions. Those services can then be queried to provide their description to a client, which can then be used to dynamically generate client code, add the service to a larger registry, systematically test the services and more. The tooling for this exists in a variety of stages, but much remains to be built to make this a viable solution.
A distributed description language helps for programmatic discovery, but can also aid in developer support and documentation. No matter how good the automation gets, a developer portal that describes what’s capable with the available services in a human readable way will always be a vital component. Much of the information required for a developer portal can be stored and shared using the same description languages, but the addition of static documentation demonstrating common use cases and workflows remains the best way to help developers build compelling applications.
Application governance and security
I have never sat in a conversation about SOA without someone bringing up governance. Centralized management of services has always been tricky and often acts as a bottleneck both in terms of performance and implementation. But what always strikes me about these conversations is how “governance” is used as a catch-all—and often interchangeably—for concerns around security, service orchestration, and control. When we talk about the governance in the context of microservices, what we’re really talking about is access control, API lifecycle management, and service routing and creation.
A truly distributed microservices architecture may have multiple layers of authorization. In many larger systems, the core services are composited into middle tier services that leverage an authorization service like Ping Identity to control access. Cloud Integration tools make it easier to compose these middle tier services both from existing microservices as well as legacy systems with a minimal amount of code. Cloud integration also enables architects to develop lightweight, independent services from existing monolithic applications, creating an abstraction layer that allows them to more easily replace those older systems with smaller, more efficient services in the future.
A solid API management platform such as TIBCO Mashery provides authentication and combined reporting for these services at the edge where developers leverage these services to build client applications. This “single pane of glass” view of those exposed web services allows for visibility into how those services are being used—visibility often lacking in older SOA implementations. Mashery also allows the repackaging of those services to target specific groups of developers and open opportunities to productive and monetize those APIs.
Interface Consistency
Adopting a microservices architecture often goes hand in hand with adopting a more distributed engineering process. Massive, monolithic cross-functional engineering teams have slowly given way to smaller teams, such as the “two-pizza” teams popularized by Amazon. While these distributed teams are expected to meet and communicate, the nature of deadline-driven development introduces loads of opportunities for developers to take shortcuts, especially when it comes to data model design. As a result, large systems often have services that overlap a great deal but are inconsistent in their naming and format. This leads to situations where a single system may have one service with a property named “first_name” and another that uses “fname”. These inconsistencies can lead to confusion and error-laden code when developers at the edge begin using these services.
Object library and modeling tools like Reprezen have emerged to make it easier to manage object definitions across large organizations. Description languages such as the OAI can also make it easier to track and identify interface inconsistencies as part of an automated testing and integration process without sacrificing service independence.
It’s becoming a cliché to say that “microservices are SOA done right.” In truth, microservices are still SOA. Whether it’s an improvement on older methods or not depends entirely on how individual teams implement them. It’s probably more accurate to say that microservices are SOA —there are a number of inherent improvements, but success is still strongly dependent on sane implementation. But with tools like solid API management, cloud integration, and distributed service descriptions, engineering teams can put themselves on the right path toward microservice success.




