

Integration
Apache Hadoop was built for processing complex computations on Big Data stores (that is, terabytes to petabytes) with a MapReduce distributed computation model that runs easily on cheap commodity hardware.
A Hadoop distribution from vendors such as Hortonworks, Cloudera or MapR packages different projects of the Hadoop ecosystem. This assures that all used versions work together smoothly. On top of the packaging, Hadoop vendors offer tooling for deployment, administration and monitoring of Hadoop clusters. Commercial support completes their offerings.
The key challenge is to integrate the input and results of Hadoop processing into the rest of the enterprise. Using just a Hadoop distribution requires a lot of complex coding for integration services.
Requirements for Integration of Apache Hadoop
On top of a Hadoop distribution, you should use a Big Data suite to solve your integration challenges by adding several further features for processing Big Data:
- Tooling: Usually, a Big Data suite is based on top of an IDE such as Eclipse. Additional plugins ease the development of Big Data applications. You can create, build, and deploy Big Data services within your familiar development environment.
- Modeling: Apache Hadoop offers the infrastructure for Hadoop clusters. However, you still have to write a lot of complex code to build your MapReduce program. You can write this code in plain Java, or you can use optimized languages such as PigLatin or the Hive Query Language (HQL), which generate MapReduce code. A Big Data suite offers graphical tooling to model your Big Data services. All required code is generated. You just have to configure your jobs (i.e. define any parameters). Creating Big Data jobs using graphical tooling is much easier and more efficient.
- Scheduling: Execution of Big Data jobs has to be scheduled and monitored. Instead of writing Cron jobs or other code for scheduling, you can use the Big Data suite for defining and managing execution plans easily, e.g. by defining graphical timers, checkpoints, or using real time SOAP or REST web service calls.
- Integration: Hadoop needs to integrate data of all different kinds of technologies and products. Besides files and SQL databases, you also have to integrate NoSQL databases, social media such as Twitter or Facebook, messages from messaging middleware or data from COTS such as Salesforce.com or SAP. A Big Data suite helps a lot by offering connectors from all these different interfaces to Hadoop and back. You do not have to write the glue code by hand, you just use the graphical tooling to integrate and map all this data.
TIBCO ActiveMatrix BusinessWorks is the service delivery platform offering all the above features. Integrate Hadoop with any web service, business process or application such as SAP or Salesforce.com.
TIBCO ActiveMatrix BusinessWorks Plugin for Big Data/Hadoop
The TIBCO ActiveMatrix BusinessWorks Plug-in for Big Data connects TIBCO ActiveMatrix BusinessWorks to Hadoop. It allows TIBCO ActiveMatrix BusinessWorks users to an established non-code approach to integrate with Hadoop’s Distributed File System (HDFS) and its batch processing frameworks, Apache Hive and Apache Pig.
TIBCO ActiveMatrix BusinessWorks uses the open Eclipse ecosystem. Installation of additional plugins can be done quickly and easily via the Eclipse Update Site within TIBCO Business Studio:
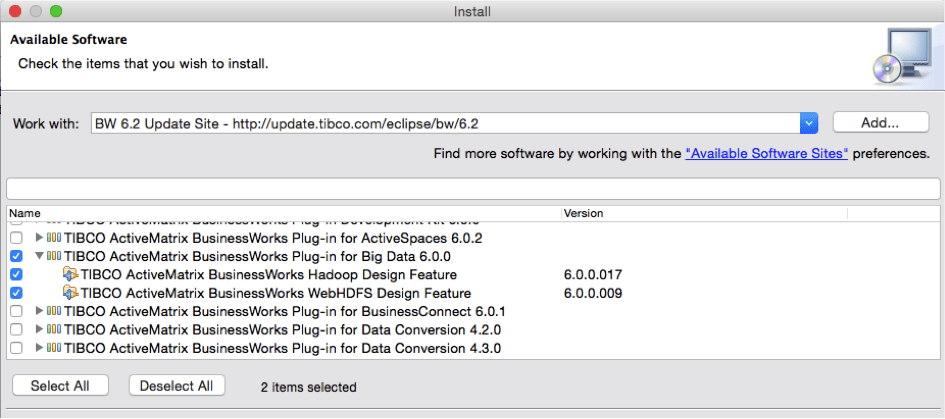
Integration of Apache Hive with BusinessWorks
Many Hadoop developers favorite Apache Hive as it offers a SQL interface. All MapReduce code is generated automatically under the hood. BusinessWorks’ Hive connector works similar to its JDBC connector for relational databases: Just configure the Hive connection details and add the SQL statement you want to execute. Input and result can be used with any other BusinessWorks activity including error handling, compensation, and all other features. That’s it! It is so easy to integrate the Hadoop ecosystem with other systems.
Like every plugin and activity, the Big Data Plugin has a sample project and tutorial, which can be used for getting started quickly:

The Hive activity is selected in the above screenshot. At the bottom, you see the SQL you have to enter here. Import this example by yourself, configure it with your Hadoop cluster, and start leveraging BusinessWorks for integration tasks.
BusinessWorks Process + MapReduce Java Code = No Problemo!
Of course, you can also write custom MapReduce code instead of using Hive or Pig. TIBCO ActiveMatrix BusinessWorks 6 offers first-class development tooling including an Eclipse Design Time, development in BusinessWorks process designer and/or native Java and a modular OSGI runtime. You can even debug BusinessWorks AND Java code within the same process using the well-known Eclipse debugger:
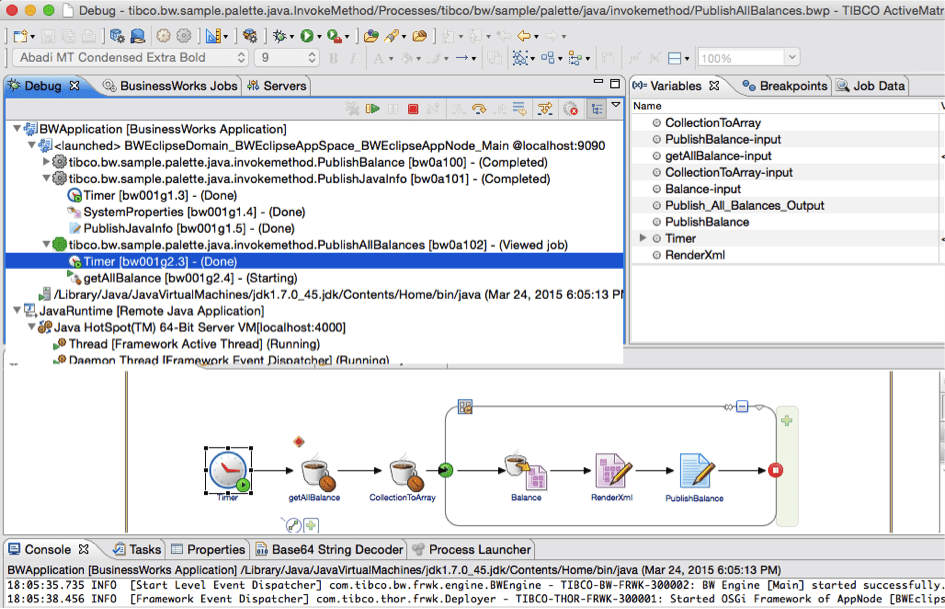
As you can see in Figure 3, the debugger runs a single process, which includes a BusinessWorks application and the Java Runtime executing a compiled Java class.
TIBCO StreamBase for Fast Data Streaming Analytics on Top of Hadoop
As TIBCO offers vendor-independent middleware for integration, event processing, and analytics, BusinessWorks can integrate with any Hadoop distribution. Therefore, no matter where you run your Hadoop processes, download BusinessWorks 6 and the Big Data Plugin here and give it a try to leverage the benefits of the leading integration tool on the middleware market.
This article explained how to integrate Hadoop Big Data processes by using its batch processing frameworks MapReduce, Pig, and Hive. Besides, Hadoop is evolving more into the direction of (near) real-time Fast Data use cases. Continue reading “TIBCO StreamBase + Hadoop + Impala = Fast Data Streaming Analytics” to find out how to realize Fast Data Hadoop use cases with TIBCO StreamBase.




