

Apache Hadoop was built for processing complex computations on Big Data stores (that is, terabytes to petabytes) with a MapReduce distributed computation model that runs easily on cheap commodity hardware. Hadoop solved several use cases, which were either way too slow or even impossible to realize with other tools.
As of today, Hadoop is evolving quickly. It is not only used for batch processing anymore. YARN, Storm, Spark, and several other solutions introduce modern paradigms to Hadoop. However, some problems still remain with Hadoop:
- No good, easy development tooling for the Hadoop ecosystem components such as Hive, Storm, Spark, etc.
- Missing maturity (a lot of alpha/beta/0.x versions) especially in management and monitoring tools, as well as security, connectivity, and APIs
- No “real time” (== seconds, milliseconds, microseconds), but “near real time” (still several seconds and more, much more when recovering from infrastructure faults)
- No operational analytics (human monitoring and proactive actions)
So why not combine the great benefits of Hadoop with the Fast Data streaming analytics tool TIBCO StreamBase with its mature, mission-critical deployments in several different industries, great graphical tooling, and operational real-time analytics (via TIBCO Live Datamart on top of StreamBase)?
This post shows how to realize a Fast Data use case with TIBCO StreamBase and the Hadoop framework’s Impala analytical database quickly and easily.
Cloudera Impala – An Analytical Database on Top of Hadoop
Impala is Cloudera’s massively parallel processing (MPP) SQL query engine for data stored in a computer cluster running Apache Hadoop. Impala enables users to issue low-latency SQL queries to data stored in HDFS (Hadoop’s distributed file system) and Apache HBase (non-relational, distributed database) without requiring data movement or transformation.
Impala is integrated with Hadoop to use the same file and data formats, metadata, security, and resource management frameworks used by MapReduce, Apache Hive, Apache Pig, and other Hadoop software. Contrary to classic Hadoop processing using MapReduce, Impala is much faster—a query response only takes a few seconds in many use cases.
TIBCO StreamBase CEP – Fast Data Stream Processing and Streaming Analytics
The TIBCO StreamBase Complex Event Processing (CEP) platform is a high-performance system for rapidly building applications that analyze and act on real-time streaming data. Using TIBCO StreamBase, you can rapidly build real-time systems and deploy them at a fraction of the cost and risk of other alternatives.
TIBCO StreamBase offers plenty of adapters for all kinds of systems and applications—for example: TIBCO EMS, TIBCO FTL, JMS, TCP, and many more. Big Data adapters for Hadoop are also available. Some customers use TIBCO StreamBase in combination with Apache Flume, Apache Kafka or Apache Storm. It is very easy to create new adapters using templates and wizards within the IDE. Therefore, the StreamBase Component Exchange (SBX) is growing every month.
Impala is JDBC-compliant. Adding Cloudera’s JDBC JARs to the Eclipse IDE-based StreamBase Studio project’s Build Path, plus adding the following element to the StreamBase server’s configuration file, is all you have to do before using Impala with your application’s graphical Query and Query Table components:
<data-sources>
<data-source name=”impala” type=”jdbc”>
<uri value=”jdbc:impala://cloudera-host:21050/;auth=noSasl”/>
<driver value=”com.cloudera.impala.jdbc4.Driver”/>
</data-source>
Real-World Use Case: Real Time Clickstream Analytics for Cross-Selling
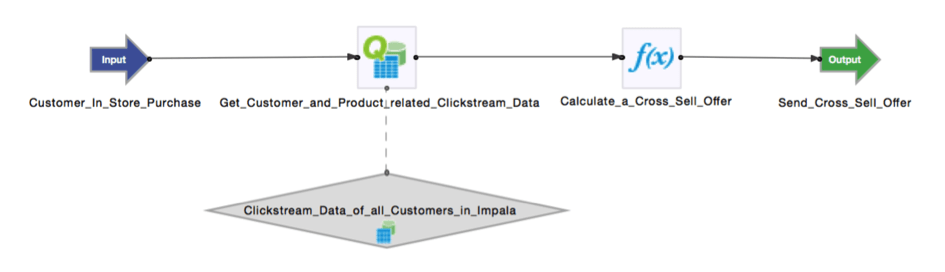
Let’s take a look at a real world example to explain how the combination of Hadoop (Big Data) and streaming analytics (Fast Data) can create business value quickly and easily: a retailer stores all clickstream data of all its customers from its e-commerce website on a Hadoop cluster. This generates up to a terabyte of clickstream data at rest, every day.
Then, let’s assume that a customer buys a product in a store. While the customer is paying for his purchase, the underlying streaming analytics TIBCO StreamBase event processing engine loads all clickstream data related to the customer from Hadoop. In addition, the application loads all clickstream data about other customers that is related to this product and not older than two hours.
All relevant data is queried and grouped by using Impala to get the data fast—before the customer has left the store. The data is aggregated and correlated in motion by TIBCO StreamBase. The engine calculates a cross-sell offer based on the analyzed clickstream data. The customer receives a 30% coupon if he purchases the product in the next two hours. Guess how much this increases the retailer’s revenue, instead of “allowing” the customer to buy the second product at a rival’s store? Other streaming data could be correlated as well, for example Salesforce CRM data, or social feeds from Twitter or Facebook.
Figure 1 shows how this use case is realized with TIBCO StreamBase:
TIBCO Spotfire – Business Intelligence and Data Discovery
If you wonder how to discover new patterns and correlations, which you would then automate with TIBCO StreamBase and Impala…
TIBCO Spotfire is analytics software that helps you quickly uncover insights for better decision-making. You use it to analyze historical data and find patterns. These patterns are then incorporated into streaming analytics. TIBCO Spotfire also has several Hadoop connectors. “Cloudera Impala and TIBCO Spotfire®: Fast Interactive Visual Analytics on Big Data” describes in detail how Spotfire connects to Impala.
TIBCO StreamBase and Apache Hadoop are Friends, not Enemies!
Now you understand how you could leverage the combination of TIBCO StreamBase and Apache Hadoop to create added business value. Think about a Fast Data use case in your company. Download TIBCO StreamBase here and add value by using streaming nalytics in combination with Big Data stores.
If you want to learn more about the combination of Business Intelligence, Apache Hadoop, and streaming analytics, then continue reading the article Real-Time Stream Processing as Game Changer in a Big Data World with Hadoop and Data Warehouse.


 Routing in TIBCO BusinessWorks™")

 Plugin")