

The term “big data” is certainly everywhere these days. There has been an explosion in the number of articles and sites dedicated to this topic, and the number of related (or unrelated, in some cases!) technologies has also increased drastically. Don’t worry… this is not another general “big data” article. Instead, it is a discussion of one particular architectural component that is often forgotten when it comes to making sense out of the volumes of data being created and collected daily within most organizations.
Typical big data architectures focus on a variety of data storage and data processing use cases. Augmenting data warehouses, providing robust/low-cost storage, and building a scalable environment for data transformation/analytics/machine learning are just a few examples. There is also the recognition that big data processing needs to include support for both “batch” and “near/real-time” workloads.
Today, many big data articles feature the value of data to the business. But a certain portion of this data only holds true value if we are able to analyze it in real time to influence current and future action. Traditional, backward-looking data analysis alone is not enough. Threats and opportunities need to be identified faster to provide maximum business value, and in today’s connected world, decisions need to be made in a timely, relevant, and contextual manner.
To address this need, the current hype typically focuses on various “streaming analytics” technologies—the use of software to analyze data “in motion,” and to derive insight from streams of data before they are stored (this is one such definition; many variations exist). This has led to discussions around architectural principles such as the “Lambda Architecture” (https://en.wikipedia.org/wiki/Lambda_architecture) and “Kappa Architecture” as approaches for augmenting “batch” processing with “stream” processing.
Regardless of what it is called, this is definitely a valuable capability, and one that should be considered as part of any big data architecture. However, this capability is not enough, as further explained in the following section. As architects we need to look at additional supporting solution approaches in order to meet the needs of the business.
One such solution approach is the need to include event-driven rule processing in the overall architecture. In my experience, the business tends to think in “rules,” with associated context and state. For example:
“If the propensity to buy a product under certain conditions exceeds X, and if this situation is triggered while a customer is browsing my website, and I have sufficient inventory at this point in time, then make offer Y.”
“If historically a piece of industrial equipment will fail in X hours under certain environmental conditions, then do Y when this pattern is detected.”
Note that in these scenarios, and in many similar scenarios across any verticals, “traditional” request-reply driven rules are not enough. A big data rule processing environment must include context, time, and state in its decision process, and support for various language metaphors (decision tables, rule templates, rule flows, event-condition-action rules, continuous queries, etc.) to handle the logic definitions required by the business. The system must also be able to handle state in a high performing manner by using technology such as in-memory data grids. Invocation of analytical models, such as those derived from historical data and represented in constructs such as R or PMML, needs to be supported in a real-time rule context.
From a TIBCO perspective, TIBCO BusinessEvents is such a system, and has been used successfully in a number of large event-driven rule implementations across the globe.
“Business event processing for the right-now business is a 21st-century development, and it is growing fast. It is a technology aimed at enabling an enterprise to take action right now, the instant information becomes available.”
David Luckham
Emeritus Professor, Electrical Engineering,
Stanford University
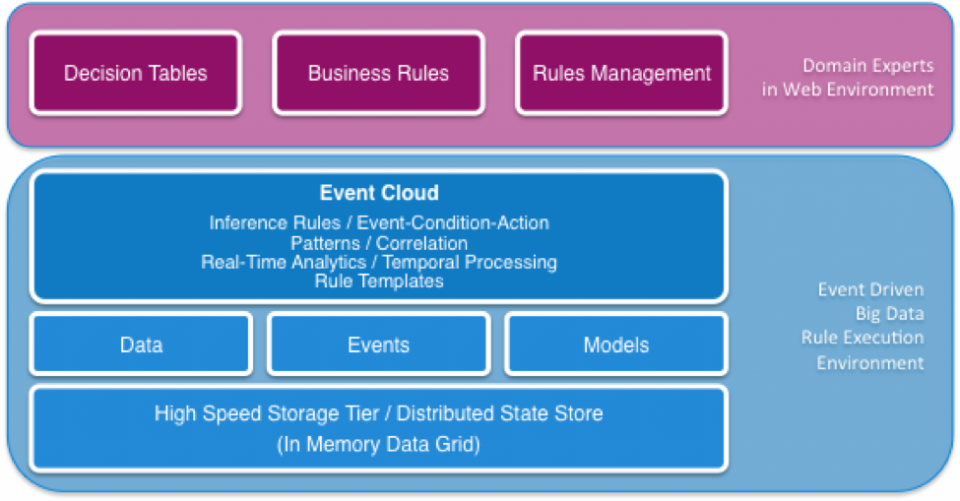
When designed and used properly, event-driven rules provide a declarative, easy-to-change environment for defining business logic. Domain-specific models allow the business to interact with the system using familiar terms and concepts, which in turn promotes agility, rapid development, and lower costs. A properly designed system also provides the business with self-service capabilities, allowing adjustments to be made quickly in response to changing business conditions.
As part of this capability, the business also needs to visualize and interact with produced decisions “as they happen.” This “actionable” visualization goes beyond simple reports and static dashboards. It instead provides a visually rich real-time view, which is often combined with historical data, into the decisions being made, the context behind the decisions, and the current “state” of key business entities and events. TIBCO delivers this “Live Datamart” function by combining push-based, continuous data feeds with rich visuals, alerting, notifications, and actions, providing users with deep insight into the current activities and performance of the business.
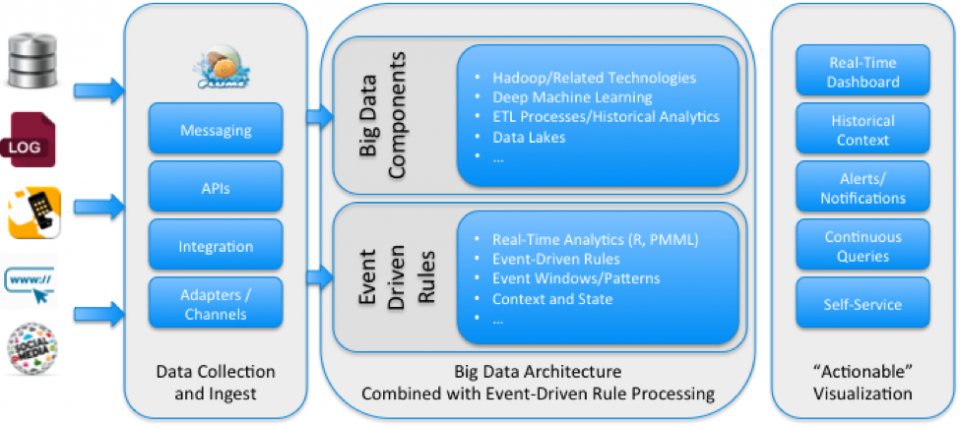
As noted, the benefits are many. Organizations need to be able to anticipate problems and opportunities. Thus, incorporating an event-driven rule processing capability into your big data architecture should be a key consideration. Combining this functionality with streaming analytics and rich real-time “actionable” visualizations provides a strong set of solution capabilities, and enables you to achieve success as we transition to this next stage of digital business.




