

Authors: Ana Costa e Silva and Anna Maria Nowakowska, TIBCO Data Science Team
In this blog series we are sharing analytic technologies that help you best leverage Big Data. In previous blogs we have shown how well you can visualize your big data with TIBCO Spotfire, regardless of the source of your data. Another important need for Big Data is to run calculations on it and to enable business users with this capability. This blog will show you how:
- A Spotfire business user can run parallel calculations on nodes in Hadoop, explaining the important steps of MapReduce.
- And how a business user can also launch calculations for all Big Data at once, using H2O.
MapReduce Parallel Calculations
An example of a calculation commonly run using historic big data is a prediction. For example a prediction of shipped volume for each product in each country. In the interface in Figure 1, the business end-user chooses ‘prod’ and ‘country’ as keys of the calculations, ‘volShip’ as the variable to predict, selects ‘Sales Predictions’ in the model section, and then presses execute.
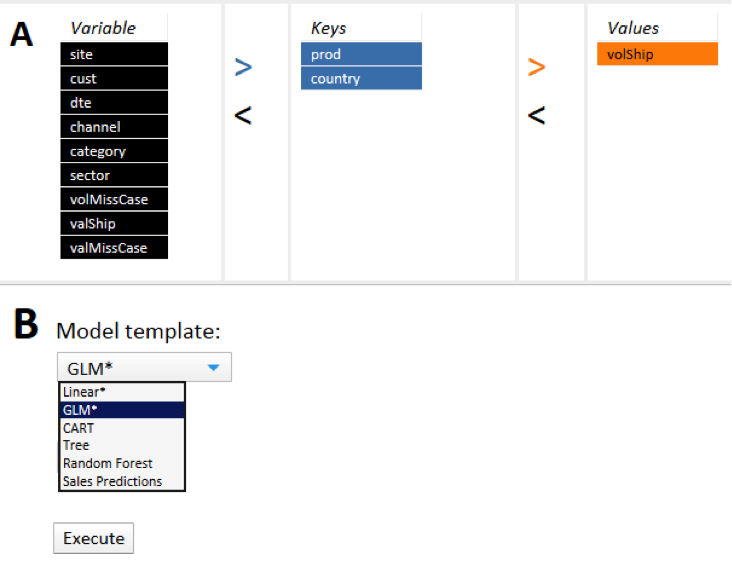
The resulting predictions are fed back into Spotfire. No need for an IT expert or a data scientist to run it. The business user himself is able to use all data available in his company to support the best possible decision. This approach is also fast: in the example above, with 333,000 rows of data per node on three nodes, the calculation takes only six seconds.
Once the model finishes, the user can explore the results in Spotfire, as shown in Figure 2 below.
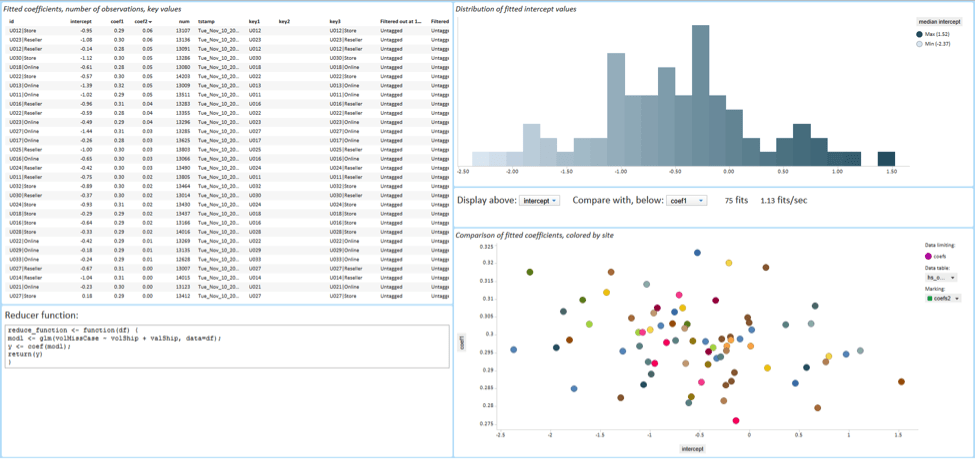
With this interface, TIBCO won the 2014 Cloudera award for the best Advanced Analytics Application.
So how is this done? A data scientist first defines the steps that provide the best possible sales prediction and places these steps behind the simple ‘Execute’ button. The data scientist creates an R script for this which is run in the background using the TERR engine embedded within Spotfire. TERR stands for TIBCO’s Enterprise Run Time for R, TIBCO’s enterprise grade interpreter for the R language. Another requirement is that IT creates the connection between Spotfire and Hadoop. Once this has been done, the interface can be reused countless times. And also the job of creating new TERR jobs to run on Hadoop data is possible without further IT support as all creation can be done within the familiar Spotfire environment.
What actually happens in the background when the business user presses the ‘execute’ button? Hadoop is a data source that is distributed over several different physical machines known as data nodes or clusters. When the user chooses to run sales predictions per country and product, he/she is running what is in Hadoop jargon called a MapReduce job. So let’s explain the MapReduce job first: In the Map step (part A of Figure 1), the user says how the data should be organised on the different nodes; in the Reduce step (part B of Figure 1) the user chooses which calculations are to run on the different nodes.
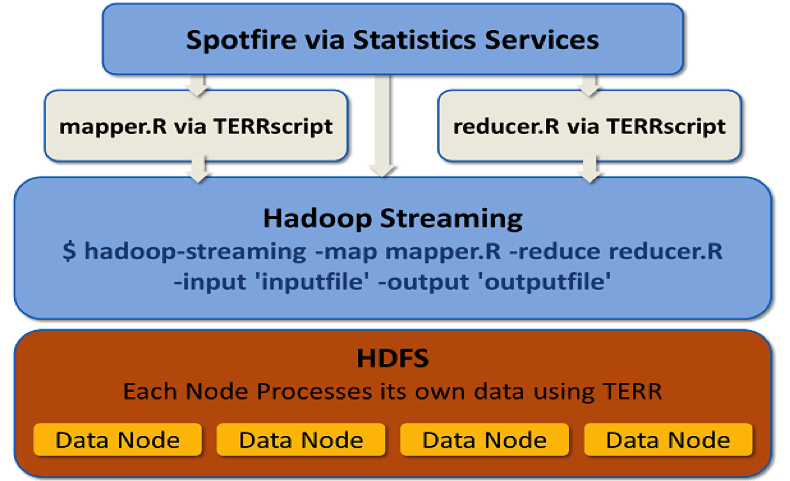
As illustrated in figure 3, in the background, these MapReduce instructions are passed to Hadoop Streaming, which is a data organizer: it arranges the data among the different nodes and ensures that all the data about one same country and product are organized on one same data node. Each of these nodes has TERR installed on it already. The reduce step contains the calculations each TERR instance must implement. The calculations run independently and in parallel in the different nodes. This is why it is possible to get such fast calculations done on Big Data. Only the relevant results, i.e. the actual predictions, are passed back into Spotfire for the business end-user to consume. Note that the end-user is never exposed to all the above and can just focus on the business need!
Single model from all your data at once: TIBCO Spotfire and H2O
We know that Hadoop is a data source that is distributed over several different physical machines known as data nodes. In the first part of this blog, we have seen how the user can set calculations to run on each node separately and in parallel, for example, make sales predictions by country and product and use Spotfire to consume the results. In this MapReduce job, the nodes work independently and do not communicate.
However, sometimes users want to run calculations on all your data at once, with all nodes talking to each other. For example, you may want a model to distinguish fraudulent transactions from all the rest, or to pick out customers who would be open to receiving a promotion for a specific product from those who would not.
The good news is that it is possible to make an easy interface for a business user to get one single model from all big data at once.
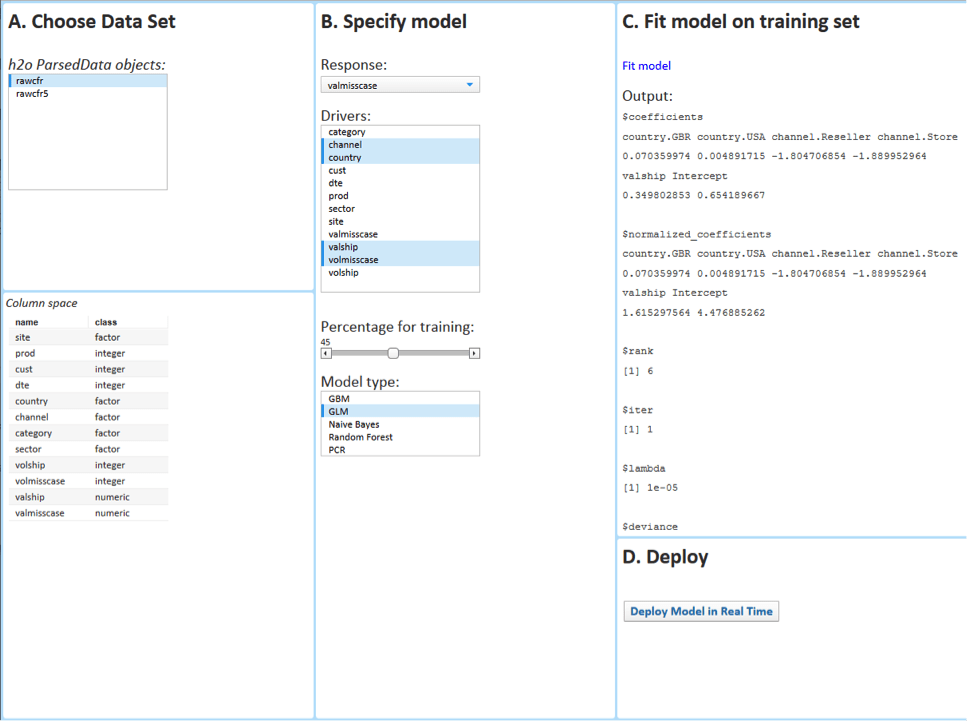
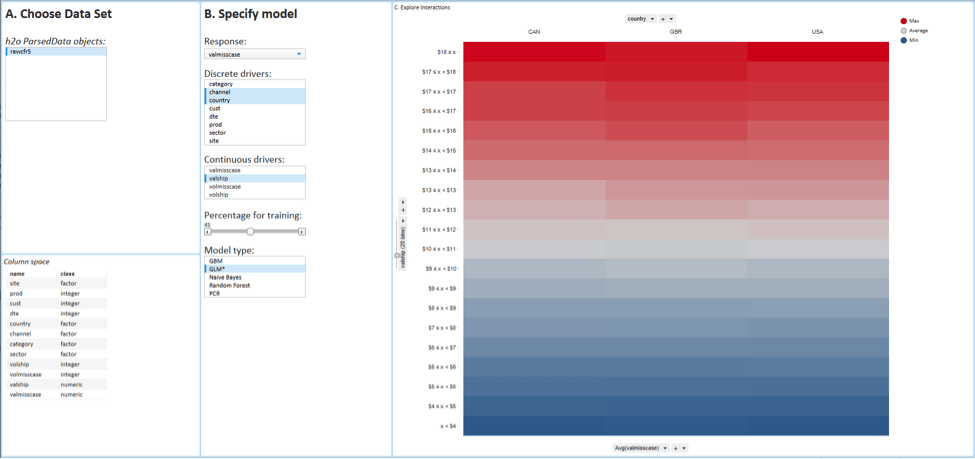
Figure 4 is an example of a Spotfire interface that the business user can use to create such a model on all his big data at once. In part A, the user chooses which dataset he wants to use. In part B, the user chooses which variable should be used in the model. In this example, the user chooses ‘valmisscase’, which is the total value of undelivered items. Just below that the user can choose which variables is believed to drive this phenomenon. In this example the total value and volume of all shipments, as well as the channel and country or origin. In model type he can choose which type of calculation he wants to run: in this example he chooses Generalized Linear Model or GLM, but it can be set up to be any model relevant to the user. In part C, he presses Fit Model and, once finished, explores model output.
In order to help with the selection of predictive variables for the model, the user can visually explore the relationship between them. Figure 5 below shows a heat map with shipment value on the y-axis and country on the x-axis. Red color signifies large values of shipment lost on the way. We see the more expensive shipments are more likely to be lost on the way. It is therefore worth including this variable as a predictor of missing shipments.
Once the model completes, the user can visually explore the results in Spotfire. Figure 6 below shows a graph of residual distribution per Channel. Figure 7 shows a measure of model effectiveness, a graph of predicted vs. actual values of missed shipments.
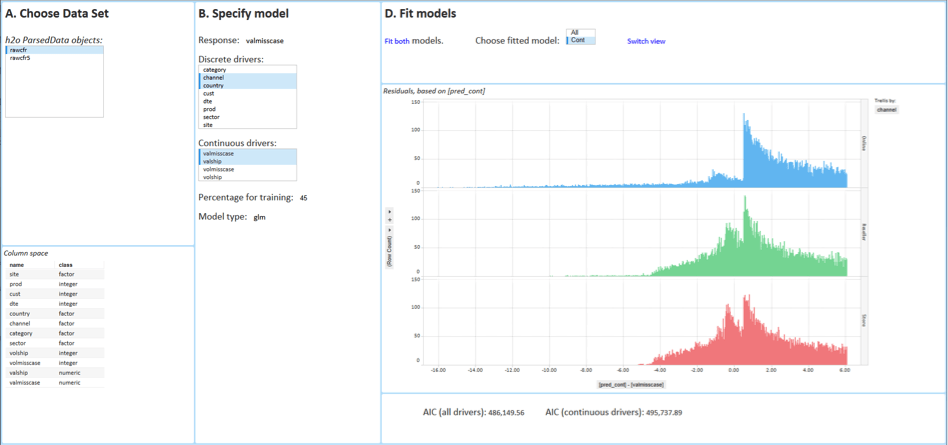
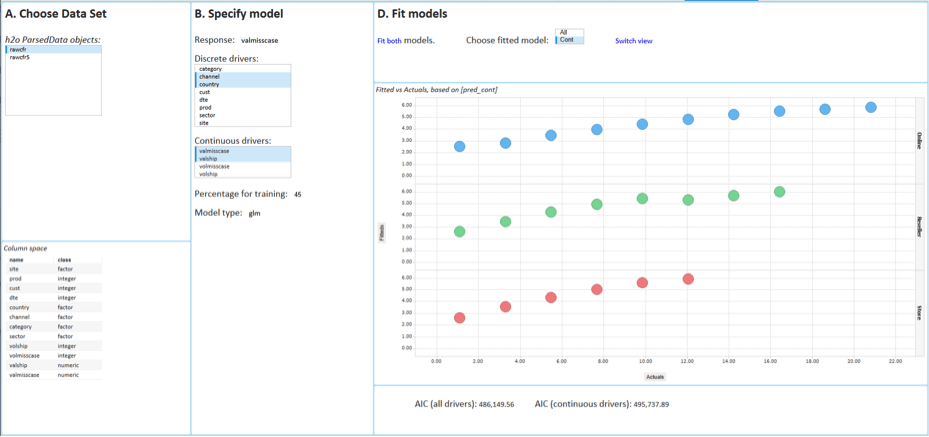
So what happens in the background, not visible to the business user? There are different ways to get one single model from distributed data: by combining MapReduce results using ensemble techniques, or using SparkR and Spark MLLib, or H2O. This specific Spotfire implementation uses H2O. H2O is an open source analytic tool and provides a combination of extraordinary math and high performance parallel processing. Calculations are run in parallel over the many nodes and the nodes communicate just enough to cooperate in the building on the best joint model. And this is done really fast. On one million rows of data distributed over 3 nodes from Amazon Web Services, H2O takes just three seconds to produce the result, which is shown under Output in Figure 4, as well as in Figures 6 and 7. The user can now evaluate the model and, once happy with it, the user can press the ‘Deploy model in real time’ button seen in Figure 4. With this, the user himself sends the model to TIBCO’s real-time event processing engine. And from that moment onward, the model will be live and shipments of merchandise will be flagged for high risk of getting lost. Or in another example, customers visiting a retailer’s Website will be receiving a promotion aligned with the latest promotional model that our business end user has just created using all his Big Data at once.
You now know of two methods for running Big Data calculations. They can be launched by business users from a simple re-usable Spotfire interface and without the business user needing a degree in maths or IT.
To learn more about Spotfire Big Data analytics solutions, visit Spotfire.
Next Steps:
- View Recorded Demo: Watch our presentation from the H2O World 2015 conference, where we present the analysis illustrated in this blog post – specific demo starts at 14min 7s and finishes at 18min 56s into the video. Full video shows TIBCO’s Fast Data story with some interesting real-time use-cases such as hard-drive and solar-cell manufacturing and predictive maintenance.
- Try Spotfire and start discovering meaningful insights in your own data.
- Subscribe to our blog to stay up to date on the latest insights and trends in Fast Data and Big Data analytics.
- Ask your TIBCO Spotfire account contact if you prefer to get TIBCO professional support in building a Spotfire Big Data calculation interface.




