

Raw data coming from a sensor, transducer, detector, or lab instrument can exist in multiple formats, which makes analysis difficult. Sometimes, the collection methodology or storage database requires data to be in a structured format which is not suitable for analysis or creating visualizations. It could be in a text file where all the data values are merged together and you need to split columns into multiple column values containing multiple pieces of information. These functions are part of Spotfire’s inline data preparation and data wrangling capabilities.
Level 1 Scenario:
When delimiter or separator is obvious and numbers of new columns is unambiguous:
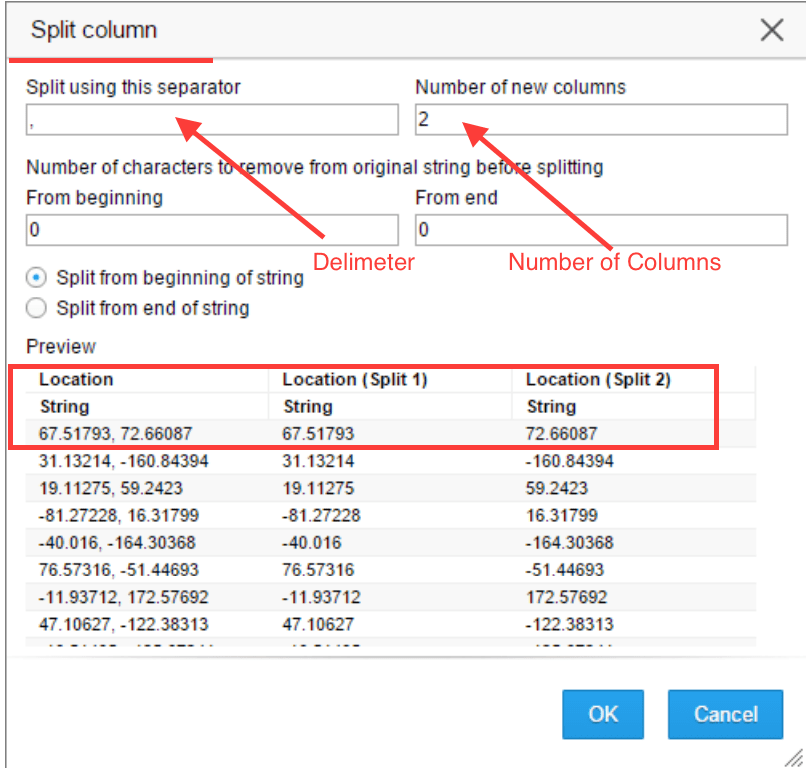
Example: Location column has both latitude and longitude together. Spotfire can automatically select a default separator based on commonly used separators and can also recommend the number of new columns. It provides flexibility to override the default and manually input values for the separator and number of new columns to generate. If required, it is possible to hide the original column from Analysis.
Level 2 Scenario:
When delimiter or separator is obvious, numbers of new columns is unambiguous but there is some extraneous information in the data:
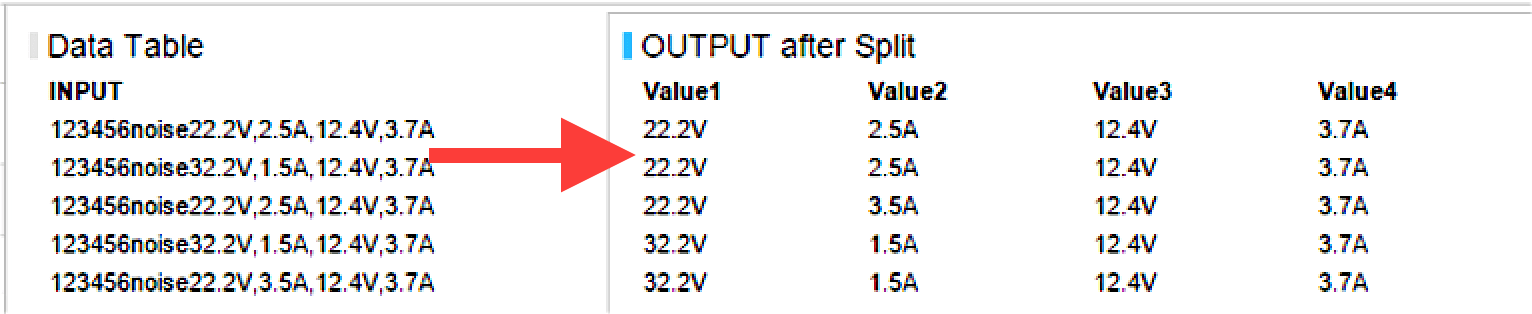
Example: Spotfire can help take out noise from the beginning or end of your string. For example, an instrument sends a few extra characters at the beginning, which are not required. The user can enter the number of characters to be ignored either at the beginning or end.
Level 3 Scenario:
When delimiter or separator is obvious but the numbers of new columns are not well-defined:
Example: Spotfire data functions can be used to resolve this issue. Based on the number of values, different numbers of columns would be generated. In this case, since key B has three colors, three columns are generated. If the maximum number of colors for any key will be 4 then four columns would be generated.

Check out this post in its original form on the TIBCO Community. And try Spotfire for free here.




